Hand-coded C++ gradients for Stan
I wrote a tutorial on a technique that isn’t in the Stan documentation: hand-coding C++ gradients to bypass Stan’s automatic differentiation system.
The short version: Stan’s autodiff is general-purpose and excellent. But when a model has millions of repetitive operations — gathering indexed parameters, computing the same likelihood across 1.5 million observations — the bookkeeping overhead can dominate the actual math. You can replace that overhead with analytic gradients, using the same internal mechanism Stan’s own developers use for built-in functions.
The tutorial walks through the full pattern, from a toy weighted sum to indexed gather-scatter operations to parallelism with reduce_sum and raw TBB. It includes a real-world case study from a hierarchical model of global football across 85+ leagues and a decade of seasons, where this technique cut the dominant likelihoods by 10x and turned a multi-day run into something more practical for iterative development.
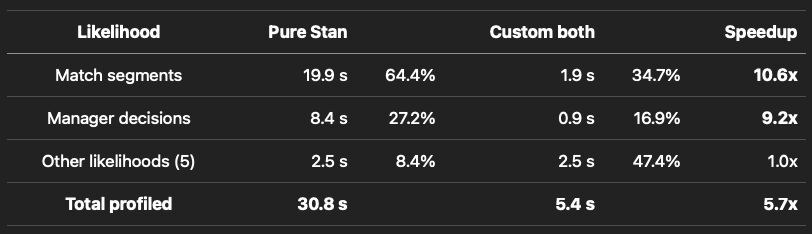
It’s the kind of optimization that only matters after you’ve already done everything else — vectorized, parallelized, profiled. But when you’re there, it’s the difference between waiting for results and working with them.