
12 Technology for interactivity
Interactivity is inherently technology dependent. We discuss modern approaches to interactivity as related to data-driven, visual graphics and narratives. As such, we will introduce a modern technology stack that includes html, css, svg, and javascript, within which technologies like d3.js (a javascript library) and processing operate. Most award-winning interactive graphics, especially from leading news organizations, use this stack.
But we can enable interactivity through interfaces, too, from R and Python interactive and markdown notebooks and code, to htmlwidgets, Shiny, and plotly. Then, we have drag-and-drop alternatives like Lyra2 or Tableau. While Tableau is functionally much more limited, a use-case for Tableau may be, for example, when a client has a license for it, wants basic interactivity for someone else to setup the visual with interactive options. The range of tools is becoming ever larger. More generally, knowing a range of tools will help us not only build our own interactive graphics, but will also help us work with specialists of these technologies.
12.1 Browsers
We’ve all been using a web browser many years. I remember pre-internet days, but some of you were probably born after it already existed! Common browsers today include Safari, Chrome, and Firefox.
All of these browsers work very similarly, in that they work with your operating system, whether a computer or smart phone or smart tablet or whatever, to listen for your actions within the browser window.
These are the same actions we discussed in the previous section. The browser watches for these events, and reports the events to things in the webpage you are reading.
12.2 Document Object Model
The web pages that load into your browser are typically named html files. These are just plain text files that contain lots of different kinds of code, which we will discuss in a moment. All that plain text is organized in something called a Document Object Model1. That’s really just a fancy word to say what I’m minimally showing you in this small example. A Document Object Model, or DOM, consists of nested pairs of tags, and a tag is written as angle bracket pairs with the name or type of tag inside them:
All webpages have the first and last tag, above, with html inside them. All pages have a tag pair with the word head inside. And all pages have a tag pair with the word body inside. The tag pair <html></html> informs the browser, “hey I’m a web page, so you know what’s inside me.” The tag pair <body></body> are where we place content that our readers generally see, what the browser displays to them. And the tag pair <head></head> instructs the browser how to format, organize, and display the content, among other things, but the instructions inside <head> tags are not actually displayed. All these tags are part of the <html> specification. Let’s consider them more closely.
12.3 Hypertext Markup Language
html2 elements are added to the content of a page to describe its structure. An element consists of an opening tag, sometimes an attribute (like a class or style), content, and a closing tag:

In the above example, the <p></p> instructs the browser to structure the content as a paragraph. There are many pre-defined tag types and attributes, and we can define our own. Also, notice that, for closing tags, a forward slash / precedes the tag name, here p, signifying the end of that element. The attribute in this example is a css (cascading style sheet) class, which I’ve named cycling_team and defined between style tags. Finally, we place our content between the opening and closing tags, whether that content is text, like “Education First” in this example, or other things like data graphics.
Duckett (2011) is helpful for the basics of html and css, which we consider next.
12.4 Cascading Style Sheets
The dimensions of content in an html document, whose dimensions can be understood in terms of boxes surrounding that content, called the “box model” where, by default width and height attributes for an element relates to the content, and the remaining space around that content is specified by its padding, border, and margin:
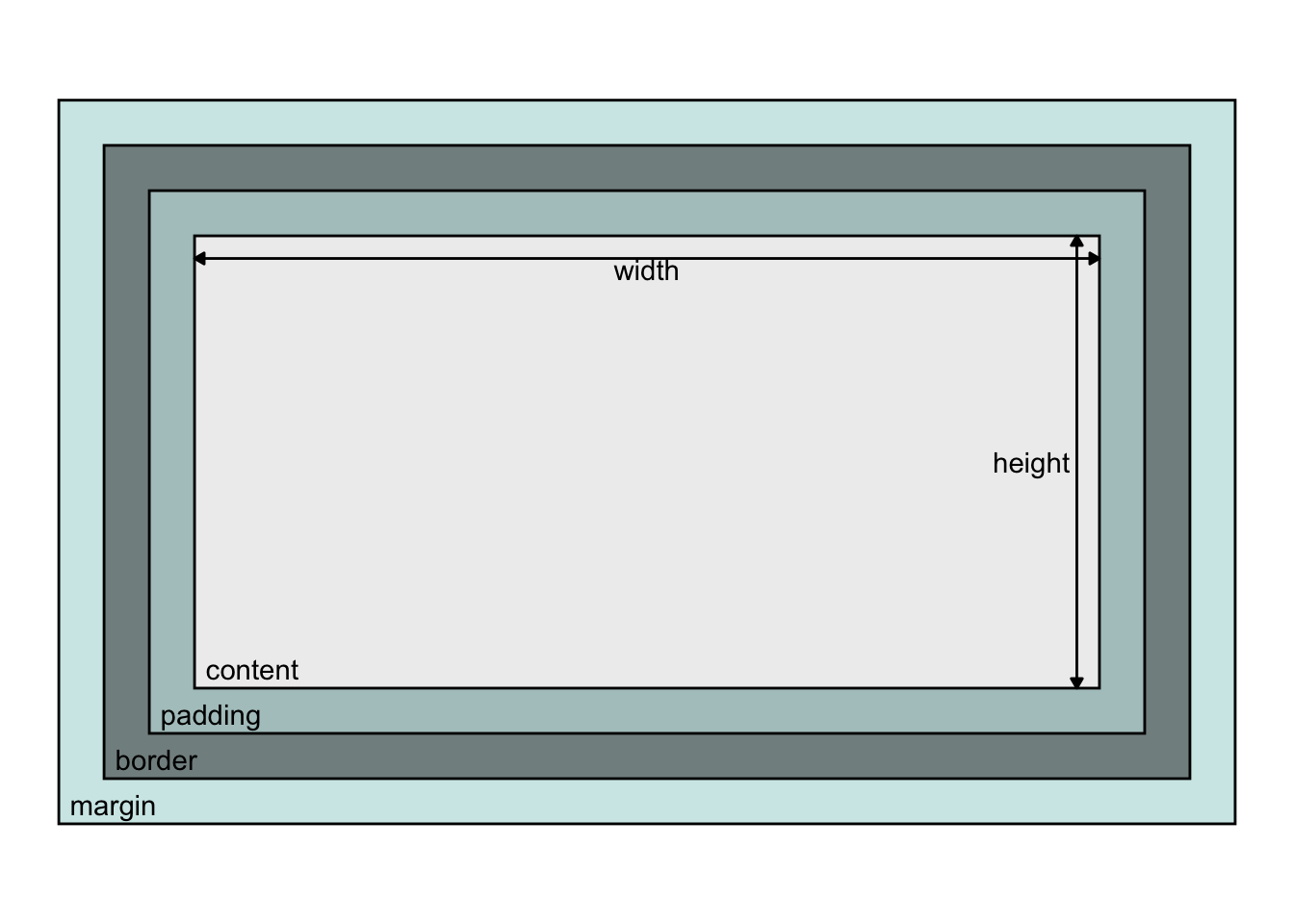
It is usually more convenient to size content by the size of the border box such that things inside shrink to fit, making combining components more predictable. This is achieved by adding box-sizing: border-box3 to css style rules.
css style rules4 Indicate how the contents of one or more elements should be displayed in the browser. Each rule has a selector and a declaration block. The selector indicates to which element(s) the rule applies. Each declaration block specifies one or more properties and corresponding values. Below, applying the class .cycling_team to a tag as an attribute,

will color the text a pink hue. css rules are specified within <style> tags:

Here, our css class sets the color of the text: Education First.
Helpful references for digging deeper into modern css include Attardi (2020); and Grant (2018). These also discuss css grid, which we consider next.
12.5 CSS grid
In earlier sections, we’ve talked about using grids to arrange things. Things like memos, proposals, and so forth. These grid are generally invisible but helps us organize and align information.
We can imagine using grids to create things like dashboards for data graphics, too. Fortunately, using grids in html pages has become straight-forward recently with advances in css, including css grid5.
As an aside, the cascading part of css means that the browser applies what you write in the order we write our classes, which means that, here, if we defined multiple classes that, say, both color text, the browser uses rules to know which thing to apply. We won’t get into the details here. Let’s consider one minimal way we can specify a css grid.
Below, we define a class .gridlayout and in that specify {display: grid;} and related properties,

Then, we use our class attributes in divider tags <div></div> to format the content. The example below displays a 2 x 3 grid of cells, each with a size specified and placed in row major order. When we create classes to format specific content — like .item or .area in this example — we include formatting information in the class. Notice that .area includes grid-column and grid-row. These refer to the boundary lines around the rows and columns where we want to place our content. When we do not specify these, like in our .item class, css grid just places the content in whatever cells are available in row-major order.
We’ll come back to grids later. First, let’s discuss the last three main technologies used for document object models.
12.6 Scalable Vector Graphics
Scalable vector graphics6 — svg — are human-readable descriptions of a collection of shapes or paths that the browser can display. As we’ve discussed, enlarging vector graphics, unlike raster-based graphics, will not reduce resolution. Together these paths and shapes comprise a graphic, which we place in the html document body between <svg> and </svg> tags:

Shapes I commonly use include the circle <circle>, rectangle <rect>, text <text>, path <path>, and group <g>. By the way, we can edit vector graphic shapes using software like Adobe Illustrator or Inkscape, too.
Of note, when we code our own shapes directly, like this, our directions differ from what we may be used to with data graphics. With those, we normally think about the origin as starting towards the lower, left corner and increasing to the right and up. For svgs it’s not quite the same. Values do increase as we move to the right, but unlike with how we typically read data graphics, the origin of an svg on a web page, or grid within the page, is the upper, left corner: values increase going down. That’s because browsers are more general than data graphics, and with web pages (in English, and many languages) we normally read starting in the top, left and read to the right, zig-zag down, and continue.
Within svg tags, we can place shapes.
The basic shapes7 we can make are very similar to what we use in a language like ggplot, the code is just a bit differently written. Recalling the most common shapes I use, a <circle> uses parameters like ggplot’s geom_circle() (actually this particular geometry is found in a ggplot2 extension package, ggforce). The <circle> example, below, with its attributes just require us to specify the center as an cx, cy coordinate location, and a radius r, then specify attributes like stroke (color), fill, stroke-width, and opacity of the fill or line to alter how it looks:


Along with <circle>, svg provides a <rect>, with attributes like geom_rect(), a <text>, like geom_text(), and a <path>, like geom_path(). And, as with ggplot’s geoms, we can change svg shape attributes like line color, fill color, stroke width, opacity, and so forth.
Because <path>8 is a little more involved, let’s consider it too. Here’s an example:

If you have ever drawn pictures by connect-the-dots, we code an svg <path> like that: a path tag or a path shape is a connect-the-dots, written as a string of letters and coordinates that we assign to the d attribute.
When we start a drawing, before we touch our pencil to paper, we locate the dot marked number 1. In svg code, that’s the command move to, or Mx,y, where x and y are the coordinates where we first put the pencil to paper. Once the pencil touches the paper, we move our pencil to the next x, y coordinate location. That’s the L command in the string above, which means “line to”. And that creates a straight line. Thus, in the above example, our “pencil” made four straight lines forming a rectangle.
Finally, we can make the line curve, the “curve to” command C, not shown in the above example. Now this command takes some practice to get well.
The curve to command, has three x, y coordinate locations. The first two coordinates are “levers” I’ve colored blue and purple here:

The last x, y coordinate for curve to C is just like the Lx,y location: it’s the final place we move our pencil.
Now, svg has significantly more functionality, but that’s all we will discuss for now. And this concludes the basics of how vector shapes are made by other programs under the hood, like ggplot.
Bellamy-Royds, Cagle, and Storey (2018) provides helpful guidance for svg.
12.7 Canvas
When performance drawing svg shapes becomes an issue—which may occur on slower computers with 1,000 to 10,000 shapes, more with today’s computers—we gain performance by switching to raster graphics. For raster graphics, we draw pixels on canvas9, which we specify within html using the <canvas></canvas> tag, shown below. From pixels, we cannot select shapes or paths like we can with svg graphics, and resolution drops upon zooming into the canvas. If for vector shapes we can edit with Inkscape, for edit rasters, edit with something like Photoshop. Here’s an example <canvas> tag:

12.8 Javascript
Now, html, css, css grid, svg, and canvas all work together to create what you see on the web page. To make them interactive, in other words to change the content or formatting we see, the browser runs code called javascript10. Javascript is a programming language that we (or our software tools) can code to listen for our (inter)actions, and react by changing the html or css or svg or whatever is needed to update in the interacted webpage.
We can bind elements to events that, upon happening, trigger javascript code, which in turn can modify content: html elements and attributes, svg or canvas, or css style. Really it can modify anything in the DOM. As with R packages that abstract and ease our application of specialized functionality, easing the burden of writing code, many javascript libraries are available to do the same.
Here is generic code to bind listeners to elements that trigger changes through functions:

Now the very basic code I’m showing above gets to the heart of how interactivity works. In javascript, we can search the DOM for a named html element or tag, and assign it as an object, here we named it element. And javascript let’s us do things to that object through functions attached to the object (this is an object-oriented programming framework). Here, the function is generically called onevent, but the event part is a placeholder for actions; here are a few specific functions: onclick, or onmouseover, or onkeypress. Our actions. The function watches for our action, on the bound element, and when it sees the action, it calls whatever function is assigned. Here I have generically called it the function functionName. And that function then does things we code, like adding a new tag element, or removing one, or changing a stroke width, or color, or really whatever we want to happen.
And that, on a very simple level, is basically how we achieve interactivity. Now as applied analysts, we may not be coding in javascript directly. Instead, some of our analysis software does, which we discuss next.
To go deeper into javascript, consult Duckett, Ruppert, and Moore (2014) for a basic understanding and Arslan (2018) for a modern, more thorough treatment.
See MDN Web Docs. CSS.↩︎